
In this issue of FSM, we interview Dr. Mark Tamplin, Lead Scientist in the Microbial Food Safety Research Unit (MFSRU) and coordinator of the ERRC Center for Excellence in Microbial Modeling and Informatics (CEMMI), a "virtual" collaborative research center operated within the U.S. Department of Agriculture-Agricultural Research Service (USDA ARS). One of five large ARS research centers in the U.S., the ERRC has six research units, including the MFSRU, which maintains a commitment to high quality basic and applied research on pathogenic bacteria and viruses to ensure a safe food supply. Research addresses high priority U.S. national needs by developing technical information and technologies needed by federal regulatory agencies, the food industry, consumers and the international scientific community.
FSM asked Dr. Tamplin, who heads up the MFSRU's Predictive Microbiology in Process Risk Models of Foodborne Pathogens program, to provide an update on the accomplishments and goals of the program and to detail the latest developments in the CEMMI project.
Food Safety Magazine: As background, would you describe the various research projects currently within the Microbial Food Safety Research Unit's Predictive Microbiology program?
Dr. Mark Tamplin: Before I do that, let me mention that there are five primary research projects within the MFSRU. These projects are reported under the USDA Current Research Information System (CRIS) which is used by USDA to track various U.S. government and academic research projects, thus providing a way to organize research projects around central themes. Each ARS project is headed by a Lead Scientist who provides technical guidance to the CRIS research program.
The five primary research projects in the MFSRU are Bacterial Stress Adaptation lead by Dr. Pina Fratamico, Quantitative Determination of Pathogen Reduction During Food Processing, directed by Dr. Vijay Juneja, Methods Development for Aquaculture headed by Dr. Gary Richards, and Microbial Genomics lead by Dr. John Luchansky, also the MFSRU Research Leader.
 Finally, the program for which I'm the Lead Scientist is a CRIS project titled Predictive Microbiology and Process Risk Models of Foodborne Pathogens, where we focus on taking the results of research on how specific environmental conditions affect the growth, survival and inactivation of bacterial pathogens and then translate those data into mathematical models that allow the user to estimate the behavior of a specific pathogen under unique environmental conditions. These models are used by the food industry to define critical control points (CCPs) in food processing operations, and in the subsequent development and implementation of Hazard Analysis & Critical Control Points (HACCP) food safety systems. In addition, these models can be used by risk assessors to define management decisions that may reduce the risk of foodborne disease. The set of microbial models that we've developed are available in the Pathogen Modeling Program (PMP) software package, which can be accessed and downloaded from our website at www.arserrc.gov/mfs/ pathogen.htm (Table 1). We estimate that about one-third of the food industry uses the PMP, and that it is currently downloaded more than 5,000 times per year.
Finally, the program for which I'm the Lead Scientist is a CRIS project titled Predictive Microbiology and Process Risk Models of Foodborne Pathogens, where we focus on taking the results of research on how specific environmental conditions affect the growth, survival and inactivation of bacterial pathogens and then translate those data into mathematical models that allow the user to estimate the behavior of a specific pathogen under unique environmental conditions. These models are used by the food industry to define critical control points (CCPs) in food processing operations, and in the subsequent development and implementation of Hazard Analysis & Critical Control Points (HACCP) food safety systems. In addition, these models can be used by risk assessors to define management decisions that may reduce the risk of foodborne disease. The set of microbial models that we've developed are available in the Pathogen Modeling Program (PMP) software package, which can be accessed and downloaded from our website at www.arserrc.gov/mfs/ pathogen.htm (Table 1). We estimate that about one-third of the food industry uses the PMP, and that it is currently downloaded more than 5,000 times per year.
Food Safety Magazine: What should industry know about the development, use and availability of predictive models available in the Pathogen Modeling Program?
Tamplin: The Pathogen Modeling Program is a software package that contains a group of models that address the growth and inactivation of bacteria, either by heat or non-thermal treatments, the latter of which include the effects of factors such as nitrites, pH, lactic acid or salt that are added to processed food. The non-thermal inactivation models, sometimes referred to as survival models, are useful for predicting the behavior of bacteria under conditions that are moderately antimicrobial, enabling the user to get an idea of how particular environments can allow microorganisms to persist and die over longer periods of time. Dr. Andy Hwang just recently joined our group to spearhead this line of research. Currently, PMP Version 6.1 encompasses 10 bacterial pathogens in a total of 38 models. With the launch of the updated Version 7.0 this summer, the number of models will increase to about 40.
Essentially, the PMP allows the user to locate a predictive microbiology model via two different menu structures: by the type of model (i.e., growth or inactivation) or by the bacterial pathogen of interest, to find out what particular models are available for that organism. For example, if you access the system by the pathogen of interest menu, say E coli O157:H7, you will find models for growth under both anaerobic and aerobic conditions, models for inactivation by heat, a non-thermal inactivation model, and a model for the effects of ionizing radiation. The user selects a model of interest and provides environmental inputs to obtain the desired predictive microbiology information. For example, if the user selects the model for growth under aerobic conditions, he or she then proceeds to input settings such as the temperature, pH, sodium chloride level or water activity. The models vary in the type of input settings available, some offering settings for phosphate, lactic acid and so on, where applicable.
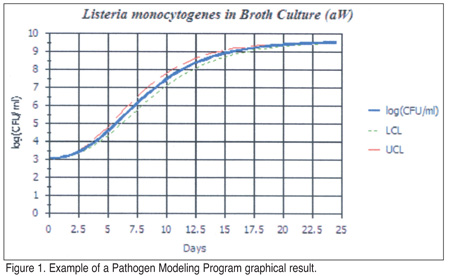 After the inputs are established, the output is provided in both tabular and graphical formats (Figure 1). The graph shows the predicted growth of the target organism which is based on your inputs. The time scale can be changed from hours to days to illustrate the rate of growth over time. The output is also in a tabular format to allow the user to export the data to spreadsheet software for further analysis. The model will provide the user with upper and lower 95% confidence limits, allowing estimates of conservative, as well as more liberal predictions.
After the inputs are established, the output is provided in both tabular and graphical formats (Figure 1). The graph shows the predicted growth of the target organism which is based on your inputs. The time scale can be changed from hours to days to illustrate the rate of growth over time. The output is also in a tabular format to allow the user to export the data to spreadsheet software for further analysis. The model will provide the user with upper and lower 95% confidence limits, allowing estimates of conservative, as well as more liberal predictions.
The PMP data are broken down into two primary phases: The lag phase, which is the period of time before the organism begins to actively grow, and the exponential phase, which is the phase where the cells actively divide. The new PMP Version 7.0 has an important new feature that will allow the user to click on a "no lag phase" icon, thereby providing predictions of growth without a lag phase. I emphasize this because the lag phase duration can vary substantially depending on the previous condition of the bacteria. For example, if you are trying to predict how Listeria monocytogenes might grow in a food processing environment, and the cells are in a robust physiological state, meaning that they have been in an environment where there is optimum temperature, pH and plenty of nutrient to grow, and then you put them onto a processed food, the lag time will normally be a relatively short period of time. However, we know that in real-world processing environments, Listeria can be found on walls, floors and drains, where sanitizers or hot water are used, all of these being suboptimal environments. This means that we are dealing with a stressed organism, which we expect will have a longer lag phase. At this time, we're not able to tell people with 100% confidence what a specific lag phase duration could be, but rather a range of potential lag phases. So when food companies, risk assessors and microbiologists want to use the PMP to estimate a worst-case scenario, and until we have better information, I suggest that they don't assume any lag phase, but rather assume that the organism, once it contaminates the food, is able to grow. This is the rationale behind the new "lag" or "no lag" optional feature in PMP 7.0.
When we're deciding what types of models to develop, we consult organizations such as the USDA Food Safety Inspection Service (FSIS), the U.S. Food and Drug Administration (FDA) and with inspectors at the FSIS Technical Center in Omaha, NE, who interact daily with industry and understand their needs in relation to predictive microbiology models. One of the identified industry needs is for models that predict bacterial behavior under changing temperatures that are typical in food processing environments. In this regard, the more highly used PMP models are those that predict the growth of organisms in foods that undergo some cooling regime.
For example, you may have a meat product that is heated, and then transferred from the cooker or oven into a cold room or ice bath where the product's temperature drops. FSIS regulations stipulate that for certain types of food there can be no more that 1 log of growth of Clostridium perfringens during the cooling process. The agency recommends certain cooling times in order to minimize growth within that requirement. Our cooling models are tools to assist the food industry with this performance standard.
Therefore, the predictive model for Clostridium perfringens is very different from the E. coli O157:H7 growth model that I mentioned earlier. In the current E. coli O157:H7 model, you can only enter one temperature, which gives you a static temperature prediction. However, because many food products, such as cured hams, undergo a changing temperature environment, a static temperature prediction is not as useful. The current PMP cooling models allow you to enter the time, the temperature and the cooling profile for five or more different combinations, and then the program calculates the subsequent bacterial growth based on a series of differential equations. As with other PMP models, the user receives the output data as mean net growth in log number of cells and the upper/lower confidence limits. You also can visualize the temperature profile and bacterial counts in a graphical form, as well as in a spreadsheet format. We are in the process of converting many of the existing static temperature PMP models into these dynamic temperature models so that they are more useful to our stakeholders in the food industry, and with regulators, risk assessors and others.
Food Safety Magazine: What are the main objectives of the Predictive Microbiology and Process Risk Models of Foodborne Pathogens researchers? How is the research going?
Tamplin: Under our current project plan, we have three primary objectives. Our first objective is to validate the existing PMP models in higher risk foods. These are foods that have been ranked by level of risk by the FSIS and FDA. When we wrote the proposal three years ago, the relevant risk assessments were those established for E. coli O157:H7 in ground beef by FSIS and for Listeria monocytogenes in RTE foods by FDA. In the latter, FDA categorized types of foods and ranked those categories by risk on a per consumption basis and a per capita basis, so we considered both of these factors and identified a need to model Listeria growth in RTE foods, specifically deli meats, soft Hispanic-style cheeses, and meat and seafood salads. Similarly, we identified data gaps in the FSIS risk assessment for E. coli O157:H7 in ground beef.
We are validating and measuring the performance of pathogen growth models so that risk assessors have more accurate models. The majority of the PMP models were developed in microbiological media, which is a defined broth for the growth of bacteria. That is not a human food, but is a food for bacteria, and so we want to verify and validate that growth rates and generation times provided by these models accurately predict what will happen in these higher risk foods for Listeria, Salmonella and E. coli. This is important particularly in cases in which there are no models for particular kinds of foods or processing and handling scenarios. In other words, risk assessors must make assumptions based on the best information available, but that information may mean that they have to assume that the growth in the food is similar to the growth of the pathogen in microbiological broth. During the risk assessment process, data gaps are identified that introduce uncertainty into the risk predictions. One way to reduce the uncertainty in risk assessment is to do the research that reduces the data gap, and therefore improve the accuracy of the prediction.
Our group's second objective involves cases in which models deviate substantially from the predictions. In this regard, we are developing new models that account for the factors that affect the application of a broth-based model to a food. For example, most of the PMP models have been developed in pure culture systems where there are no competing organisms, but in the real marketplace, most foods that we eat are not sterile, unless they are canned. In many cases, naturally-occurring spoilage organisms at low storage temperatures will inhibit the growth of pathogens, and so our new models must take into account this very significant effect of microbial competition. Dr. Tom Oscar in our group is directing a research program that focuses on developing models for the behavior of Salmonella on chicken products in the presence of spoilage organisms.
In addition, we are taking into account strain variation. Many models are developed using only one or a few microbial strains, so we're expanding the number of strains that we use in the development of models so that the model predictions are more representative of the species as a whole. We also want to produce models that take into account the previous physiological history of the organism. To do this, we will "stress out" the organisms and then compare these with "healthy" organisms to understand more about the variability in the lag phase, thus allowing us to see what the maximum and shortest durations are for the lag phase.
For example, our E. coli ground beef research has shown some very interesting reasons why this is important. The current PMP model for the growth of E. coli O157 at 10C (50F) predicts a lag phase of two days (or no growth). We observed that, in fact, there can be no lag phase in ground beef even down to 6C (43F); the organism begins growing very slowly the moment it contacts the beef. While the PMP model shows that there is no growth for two days, the research shows that there actually is growth for two days, albeit very slow growth. So the current PMP E. coli O157:H7 model can be underestimating what is happening. In addition, the PMP model shows that there is no growth at 9C, which is true for microbiological broth. However, our research shows that in raw ground beef, E. coli will grow at a temperature as low as 6C. This is how our validation research shows us where these models deviate from the broth models, and consequently we're publishing new models for the growth of E. coli O157 in ground beef that take into account strain variation, history of the organism, and so on.
Our third project objective involves a nontraditional area in predictive microbiology, one which is headed up by Dr. Rolando Flores. Dr. Flores is an agricultural engineer with extensive experience in developing mathematical process models for the wheat flour industry. We were interested in his perspective on bacteria as particles and whether he could develop similar types of process risk models for bacterial pathogens. In many food processing environments, the temperature is cold and pathogens do not grow. Although not multiplying, they are being dispersed in the environment. Dr. Flores' research first focused on understanding how a meat grinder disperses E. coli O157:H7 in ground beef. For example, if you have beef trim that's ready to go from a combo bin to a grinder and one of those trims has E. coli O157 on it, he looked at how that E. coli would be dispersed on the ground product. He developed mathematical models for how the pathogen is dispersed, as well as noting parts of the grinder that could be contaminated, which might lead to recommendations about better sanitary design of equipment.
Currently, Dr. Flores is looking at how bacteria are transferred among food-contact surfaces. When bacteria are on a piece of meat or when that piece of meat comes into contact with a knife, a glove or a cutting board, how much of the bacteria moves from one surface to the other? Putting a number to this is called a transfer coefficient, which are used in risk assessment when the aim is to model how contamination moves around a food processing plant and to estimate the amount of transfer that could occur between surfaces.
Food Safety Magazine: You also coordinate the Center for Excellence in Microbiology and Informatics, Dr. Tamplin. What is CEMMI, how was it created and what are its main objectives?
Tamplin: In January 2002, we launched CEMMI, a Web-based virtual center to bring together scientists in the predictive microbiology community to foster the exchange of information and to assist them in identifying projects and other scientists who can help them with particular research needs related to modeling. CEMMI was the idea of ERRC Center Director, Dr. John Cherry, who recognized that we have quite a number of scientists at ERRC who are doing research that is related to the development of mathematical models used to predict bacterial behavior in different environments. Dr. Cherry asked several of us to examine the issues and needs relevant to the microbial modeling community and to develop a way to organize and disseminate information related to microbial modeling. We subsequently produced a website where collaborators can "meet" other researchers interested in modeling and to work as a team to solve questions that depend on model development.
A good example of the success of CEMMI in advancing the use of predictive models of microorganisms in food is a collaborative project that has resulted in a new outreach tool, COMBASE, that will be launched at the Fourth International Predictive Microbiology Conference in Quimper, France, the week of June 15, 2003. This collaborative project began in July 2000, when internationally known predictive microbiologist Dr. Jozsef Baranyi of the Institute of Food Research in Norwich, England, informed our group that his group was also interested in archiving predictive microbiology data to enhance its use for modeling research. Dr. Baranyi is well known for introducing new types of mathematical equations that can be used to fit data of the growth or inactivation of bacteria and his models have become very important in the field. We had a similar interest in archiving the data that our research group had produced--the backbone to our PMP microbial models--which is comprised of very large quantities of data that can be used to develop and improve models for use in quantitative microbial risk assessment of foods.
Dr. Baranyi's group had already developed a structure for organizing the data, and we had approximately 5,000 data sets that we wanted to archive, so we decided to join forces. Under CEMMI, our group was able to develop the Internet browser for this database project. The product of this highly two-way collaboration with Dr. Baranyi and his associates is called COMBASE, which stands for "common database."
Highlighted on the CEMMI website, COMBASE a free database accessible to scientists, risk assessors and others, and currently one that contains about 15,000 data sets. It will be launched on the Internet in June 2003 at http://wyndmoor.arserrc.gov/combase/. The scientific community can browse for items of interest by organism, by type of food, or by investigator's name. For example, a user who is interested in how Listeria might grow in a specific environment can input the temperature, pH and water activity, the database searches on that input criteria and presents data that can be used to help you develop your own models, to compare your models to others, or to help you to observe how organisms behave in certain environments. We encourage our stakeholders to visit the CEMMI site and try the database. Comments are always appreciated to improve the product.
There are several other projects we have done within the framework of CEMMI, including an ongoing collaboration with a group in Japan to develop microbial models related to the thermal inactivation of Bacillus subtilus and a project involving the translation of the PMP into Chinese. PMP Version 7.0 also is being translated into Spanish, increasing the user base for these models.
Also, a collaboration with a Canadian group of researchers has resulted in the development of a very exciting tool that we hope to make available to stakeholders this fall. The Expert System is a decision support tool on the Web that will help people who use models for applications in food systems or who are making decisions related to food safety management, to find predictive microbiological information, including models and data sets within COMBASE, and to help them interpret those data.
For example, at the input screen, the user will be able to do many of the things I've mentioned--input the type of organism, the growth scenarios, a particular temperature range or level of water activity in a particular food type--but instead of just one model provided as your output, we're going to give you the whole gamut. You are going to get all of the models that we have that meet your search criteria, all the data sets that match it, the scientific publications that match it, and a list of links to resources that also might be of interest to the user. Expert systems are very helpful to people who make food safety decisions. We will also be able to qualify the modeling information that we give to people so they will be able to interpret those data better.
Again, more information on the research products coming out this summer and fall, including COMBASE, PMP Version 7.0 and the Expert System, can be found on our website at www.arserrc.gov/mfs/pathogen.htm. For more information on the ERRC units and current research projects, go to www.arserrc.gov.
Mark L. Tamplin, Ph.D., is a microbiologist with the U.S. Department of Agriculture (USDA) Agriculture Research Service's Eastern Regional Research Center (ARS ERRC) in Wyndmoor, PA, where he is Lead Scientist of the Predictive Microbiology and Process Risk Models of Foodborne Pathogens project team and the coordinator of the ARS Center for Excellence in Microbial Modeling and Informatics (CEMMI). Previously, Tamplin was an associate professor at the Institute of Food and Agricultural Sciences, University of Florida, Gainesville, a research microbiologist with the Fishery Research Branch of the U.S. Food and Drug Administration (FDA), Dauphin Island, AL, and an assistant research scientist at the Center of Marine Biotechnology at the University of Maryland.
The recipient of an Outstanding Researcher Award from FDA, a Research Achievement Award from the University of Florida and the Sigma Xi Research Award, Tamplin's professional advisory activities include service as a member of the National Advisory Committee for the Microbiological Criteria of Foods (NACMCF) and membership in professional societies such as the International Association for Food Protection, the Institute of Food Technologists and the American Society for Microbiology. He also has been a consultant to several South American Ministries of Health, to the U.S.-Caribbean Food Safety Initiative, the Pan American Health Organization, the U.S. Environmental Protection Agency, the National Oceanic and Atmospheric Administration, and the U.S. Centers for Disease Control and Prevention, among others. Tamplin can be reached at mtamplin@arserrc.gov.



